

With the continuing journey towards microservice architectures, Event-Driven Architectures have become highly popular. Its flexibility is rooted in a structure centered around the concept of Events which gives a product the ability to organize disparate services asynchronously with fewer overall dependencies. The volume and variety of data processing make EDA a good candidate for many platforms. This post will discuss some of the pros and cons of using EDA high-level architectures, how EDA could work in an example application, and implementation considerations when using Kafka or RabbitMQ.
From monoliths to Bounded Contexts with REST APIs.
For many years, we built large services which all shared one central database. Before we had docker containers and cloud hosting, operating a large fleet of independent processes was very challenging. Because of this, frequently there would only be a single monolithic process deployed onto large farms of physical or virtual servers. Databases were centrally managed and run on expensive servers to most efficiently take advantage of the central database systems.
Over time, software and teams became larger and most everyone moved to an agile methodology of continuous integration and continuous deployment. With this shift, the monolith started to be broken into pieces (Bounded Contexts) which were owned and controlled by independent teams. This allowed for decoupled development and deployment.
This transition moved us away from building single large applications and towards building platforms of decoupled components, all trying to work together to solve business needs. These new components need to communicate with each other — REST APIs were one of the main ways this was accomplished. With this architecture, a bounded context was wholly responsible for its data, generally stored in a persistent data store backend like a database or KV store. One bounded context was not permitted to directly access the database of another bounded context, all-access needed to be done via exposed APIs.
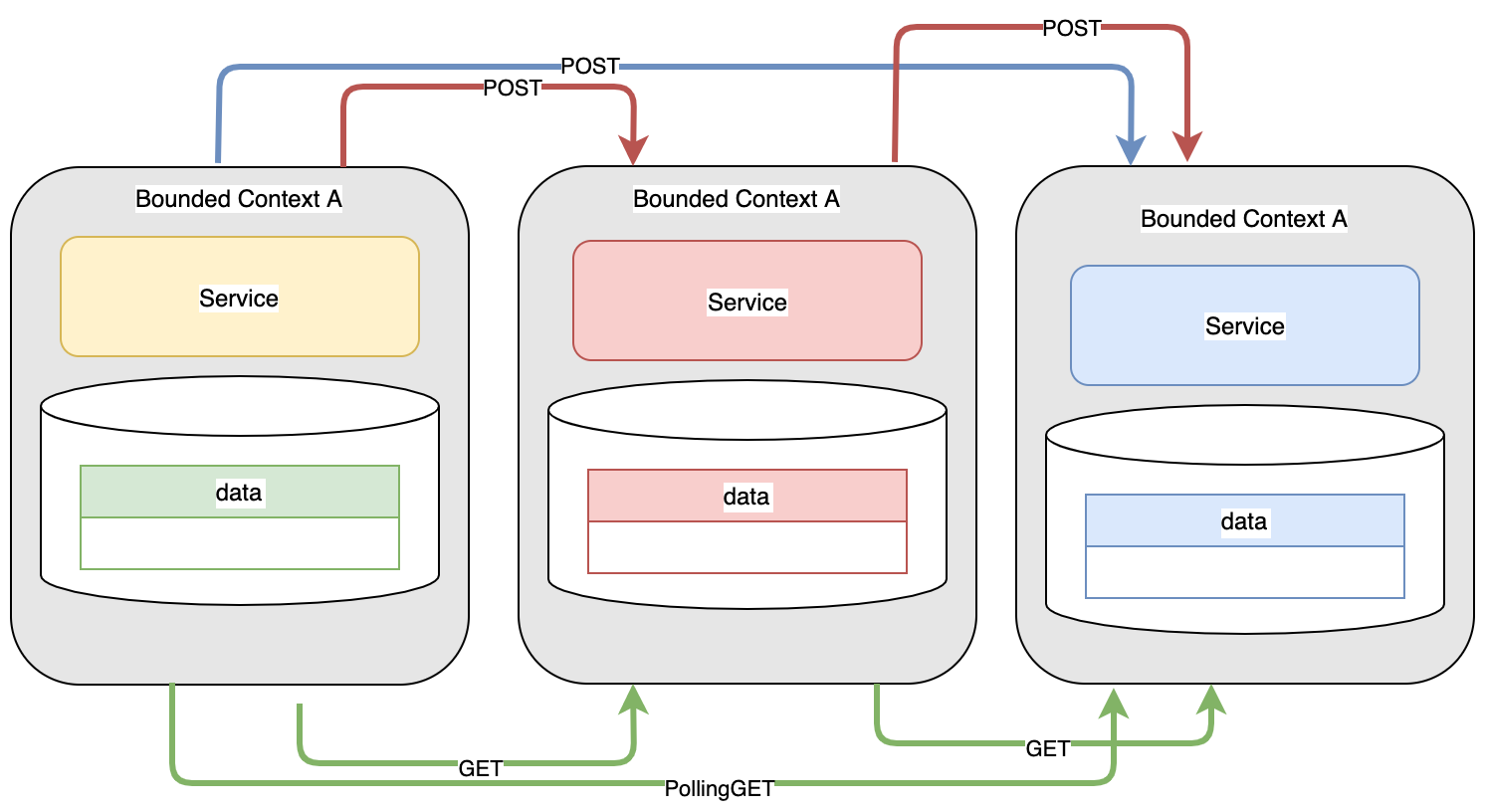
Although this design allowed the monolith to be broken up, it also added new challenges:
- Internal services often need new endpoints to perform elevated capabilities (i.e deletions) which should not be exposed to customers. Merging these two endpoint capabilities into a single service adds considerable code complexity and maintenance complications. Internal services may need polling capabilities to be aware of any data which changes within a bounded context.
- Example: A user changed their email address. Another bounded context builds its own local store of the customer information. It would be unaware of the changes unless it performed continual change polling.
- These new endpoints needed just for internal communication have an added different, and potentially more complicated, security AuthN/AuthZ requirements than customer facing endpoints.
- When one bounded context needs to link to another context, there are often latency and availability concerns. If context A needs to talk to context B which needs to talk to context C to fulfil one request, there is a latency and availability chain. Any outages or delays in any context can compound and result in an unacceptable customer experience. Added complex circuit breaker and service feature degradation logic need to be added to all pathways in the code base.
- When two bounded contexts interact, services in the target context need to be scaled to be performant and available to support the synchronous burst needs of every calling services — many of which could all call at the same time. Any degradation of any link in this complex chain could again cause serious performance issues.
What is an Event-Driven Architecture and where can it help us?
Overcoming these challenges brought us to the Event-Driven Architecture. What is it?
I define it as an architecture having decoupled services that mainly communicate with each other asynchronously by publishing and consuming data from queues.
When an event happens in a bounded context (e.g. a user changes their email or password, an order is placed, a customer adds something to a shopping cart, the backend count of an object in our inventory changes), those events are published to queues. Interested services within a bounded context (including that of the publisher) can subscribe to those queues and receive those events, to be acted upon as needed.
One of the biggest advantages of this architecture is we get is the ability to do decoupling:
- Services can be independent and don’t need to know about each other – changes to one doesn’t need to affect the other
- Services can fail independently of each other
- Services can scale independently of each other — because communication is asynchronous, latency in one doesn’t affect the other
- Services can be developed independently of each other and their teams work independently from each other
- Services could be written in the most appropriate languages as long as they can all access a common queueing technology
An Example Application
To help us understand some of the use cases, we are going to walk through a fake online shopping application from monolith to microservices with EDA.
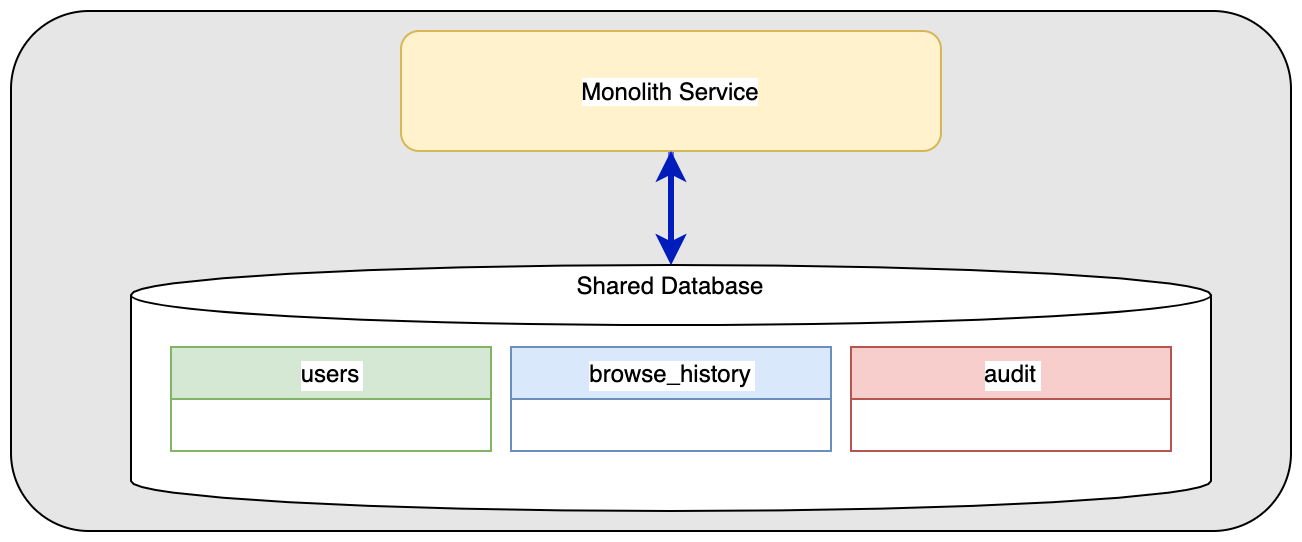
The Original Monolith
In our sample application, we have one service with tables on a shared database. The three tables we are discussing:
- a table containing the users
- a table with the history of product browsing for making recommendations
- a table with a journal of all customer actions for auditing purposes
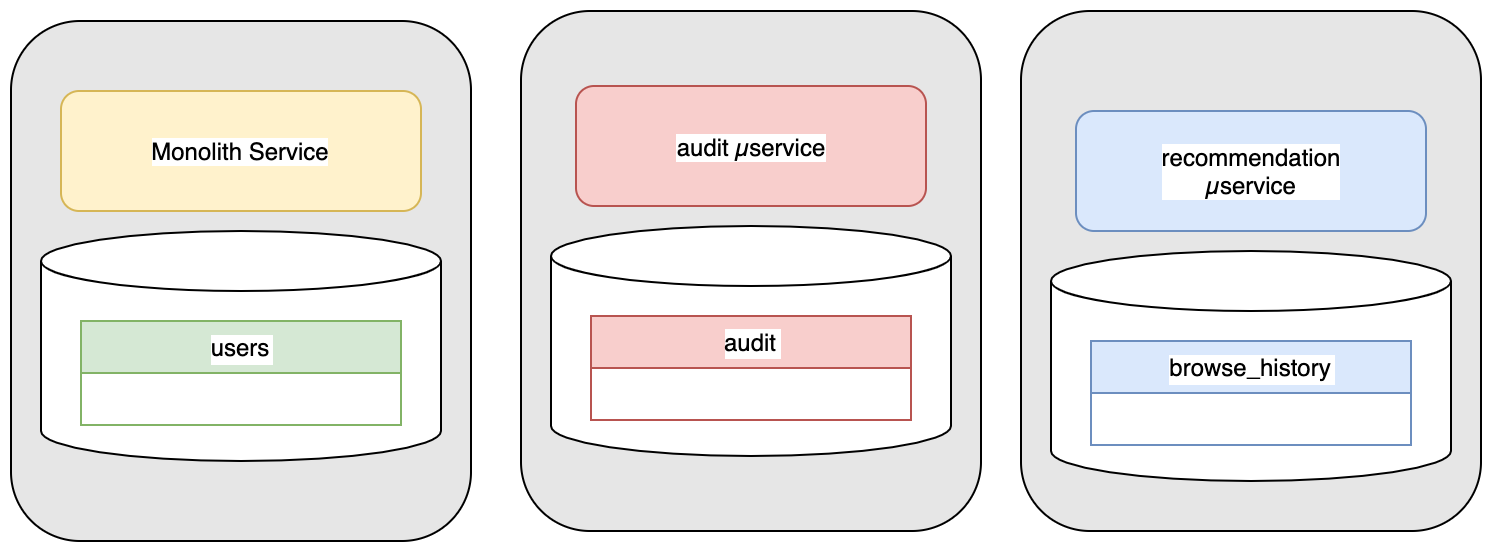
Services and REST API
As the business expands and grows, we want to break out the single service into 3 independent bounded contexts which are designed, maintained, and operated by independent teams. This gives each team the ability to adjust their scale, performance needs and schema independently. The remainder of the product capabilities remains in the monolith.
With this new design, we need some way to get information from the monolith to the reservation and audit services.
One common way would be to provide a REST-based API interface for the new services which the monolith would then connect to and POST events when they occur.
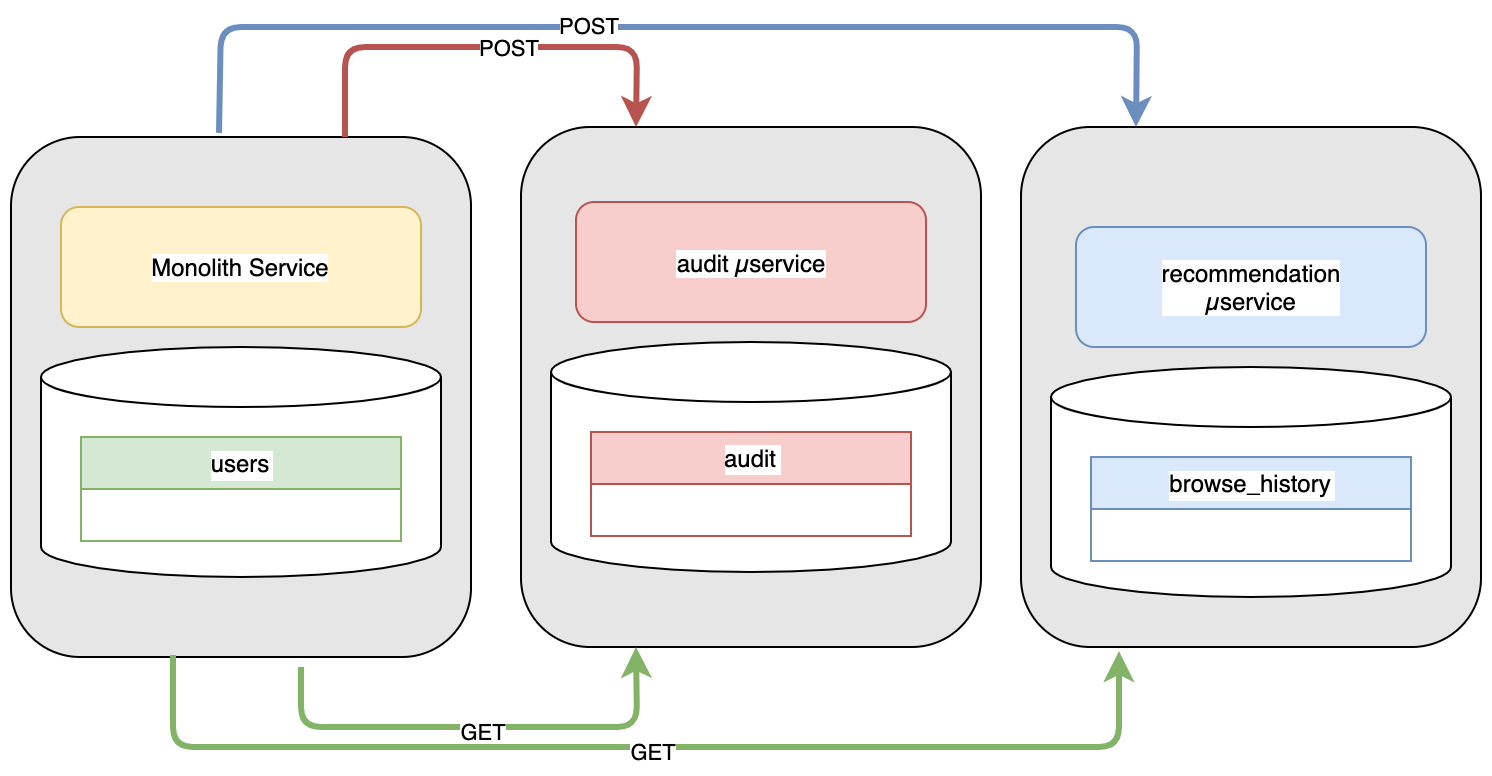
There are a few problems with this technique:
- The monolith needs to perform synchronous REST calls to the new services. Because the monolith might need to be waiting on the microservices, the user experience could be delayed. Some elements of this could be mitigated with asynchronous programming languages
- Because the monolith needs to reach out to other services, that service needs to be available and responsive. If the microservice happens to be down for whatever reason, we need to build circuit-breaker logic into the monolith to handle the exceptions
- The API for the microservice must be more tightly maintained and kept in sync with the monolith to ensure compatibility. If the microservice API is updated, it is desirable to update all internal consumers of the API to access the most recent capabilities. The owner of the microservices will need to be very considerate of all the API consumers any time changes are made.
- All microservices must be continually scaled in lockstep with the monolith to support the needs of the burst query needs of the monolith.
- Although REST APIs aren’t very complicated, there is the added development and maintenance to receive data from the monolith. Many microservices could be developed with just GET endpoints but receiving writes would likely also require PUT/POST endpoint capabilities with considerable data validation and AuthN/AuthZ development.
Event Driven Architectures with the Trilateral API
To get around these struggles, we move to a Trilateral API:
- A REST Interface used for general external services (often customer-facing) explicit synchronous requests.
- An event production interface to publish to queues the information which other outside services may be interested in.
- An event consumption interface to read from queues with information the bounded context is interested in.
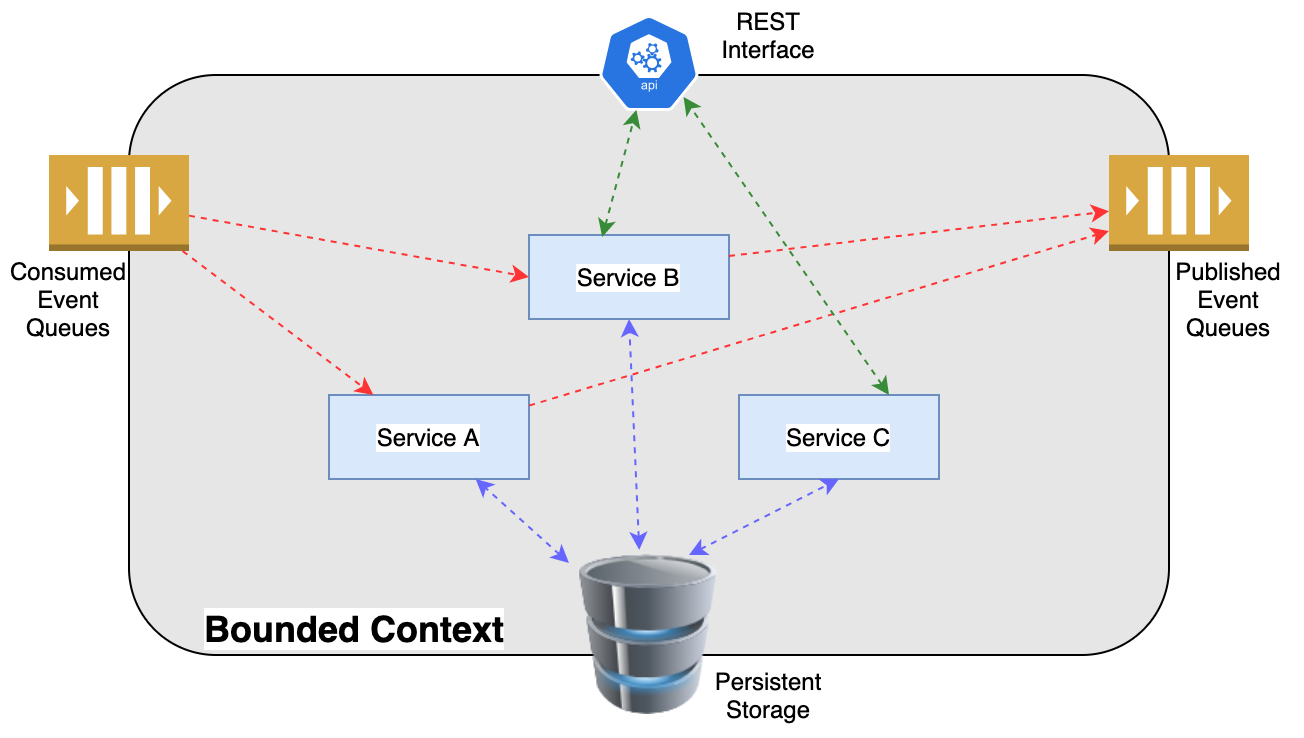
This architecture solves many of the design changes we saw earlier:
- No (or at least minimal) internal endpoints need to be created. Most API REST endpoints are for external services which don’t have their own data representation and are unable to consume from the event queues (like React interfaces). Polling by external services is longer needed since events would be published to event queues for interested services to listen to. External bounded contexts don’t need command and control REST endpoints since those commands can be events consumed from event queues
- AuthN/AuthZ can be controlled on the queue level for producers and consumers. This is independent from customer-facing AuthN/AuthZ control
- There is no latency or availability coupling since information travels between the bounded contexts via asynchronous event queues. If the producing bounded context is down or slow, interested services won’t receive new data until recovered. If the consuming bounded context is down or slow, events are buffered in the event queues
- Producing and consuming services within a bounded context are scaled based upon the steady-state event volume of data they need to process and the speed at which they can process it. Traffic bursts are buffered in the queues.
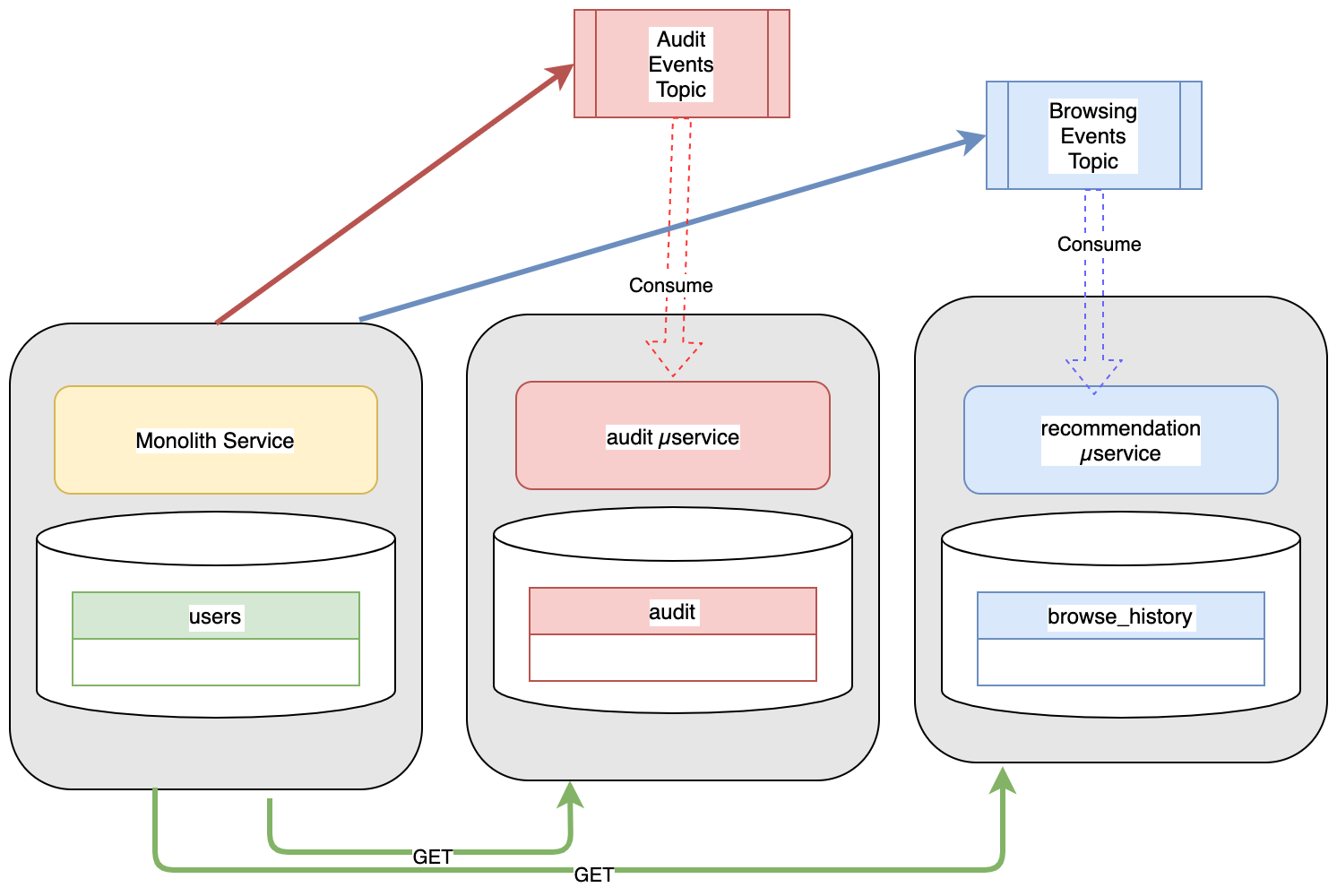
With the Trilateral API, we get the following updates to our design:
- The monolith publishes audit events to an audit queue
- The monolith publishes browser events to a browsing queue
- The audit service consumes events from the audit queue, filters for data which is important and persists those to it’s database. It’s likely that we could scale the audit service to be small since there is very little computational work needed to process the select audit events which we want to save.
- The recommendation service consumes events from the browsing queue, filters for data which is important and uses those to update recommendations for customers. We can scale the recommendation service to whatever scale is appropriate based on the computation complexity of updating recommendations.
How to implement this with Kafka and Rabbit MQ
So this sounds good and something we want to do, how do we use queueing technologies to make it happen?
Two very popular queueing systems are Kafka and RabbitMQ. Both are powerful, mature, and well-maintained tools with broad support from industry and cloud providers. There are many others, with different design goals, which we will not be discussing in this post. This will be an oversimplification of both Kafka and RabbitMQ; they are both pretty complicated and have a ton of nuances. Before either of these should be used in production, there will be a ton of reading and testing that should be done depending on the business needs and engineering skills.
While I’ve used Kafka heavily in production, I have only done lab-based work with RabbitMQ. If there are any errors or omissions with my RabbitMQ descriptions, please contact me with corrections.
Publishing and Consuming
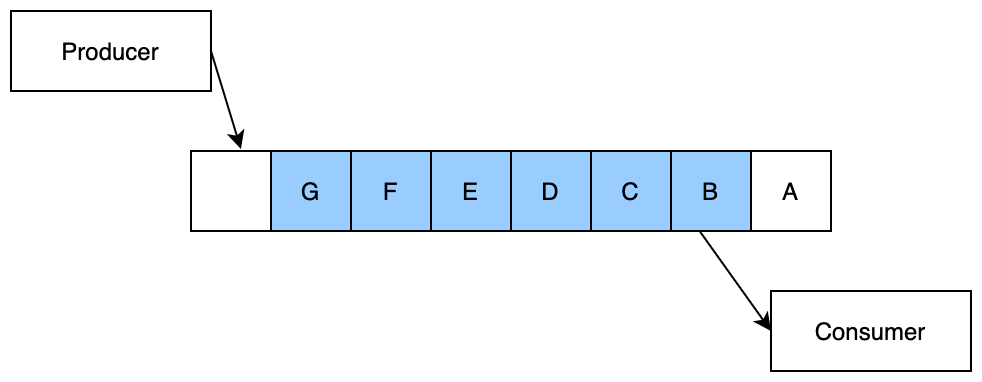
Both Kafka and RabbitMQ have producers and consumers. The data stored in the middle is called a Topic for Kafka and a Queue for RabbitMQ . In the below image, a producer has published (produced) 7 events to a queue (A through G). The consumer has consumed event A and is ready to consume event B.
With Kafka, a producer writes to topics that are usually split into multiple partitions and then spread over a group of brokers. Consumers connect to the brokers as part of a consumer group persists a recorded offset.
With RabbitMQ, a producer writes to an exchange which then pushes the events into queues on a single host for specific consumers. Consumers reading from a queue are competing consumers.
For both systems, an offset (pointing to B in the previous image) is tracked within the clusters to know which events the consumer has completed processing. When the consumer fails or is restarted, it would resume from the same offset because the cluster knows where it left off.
One important difference between tools: Kafka is intended to keep (persist) a history of events (topic retention) while RabbitMQ is designed to delete the event it once processed from a queue.
Most of these queueing systems are intended to work with small events (a few KB) but I’ve used Kafka to persist 100Mb events (patient medical histories in this case).
Kafka Innards
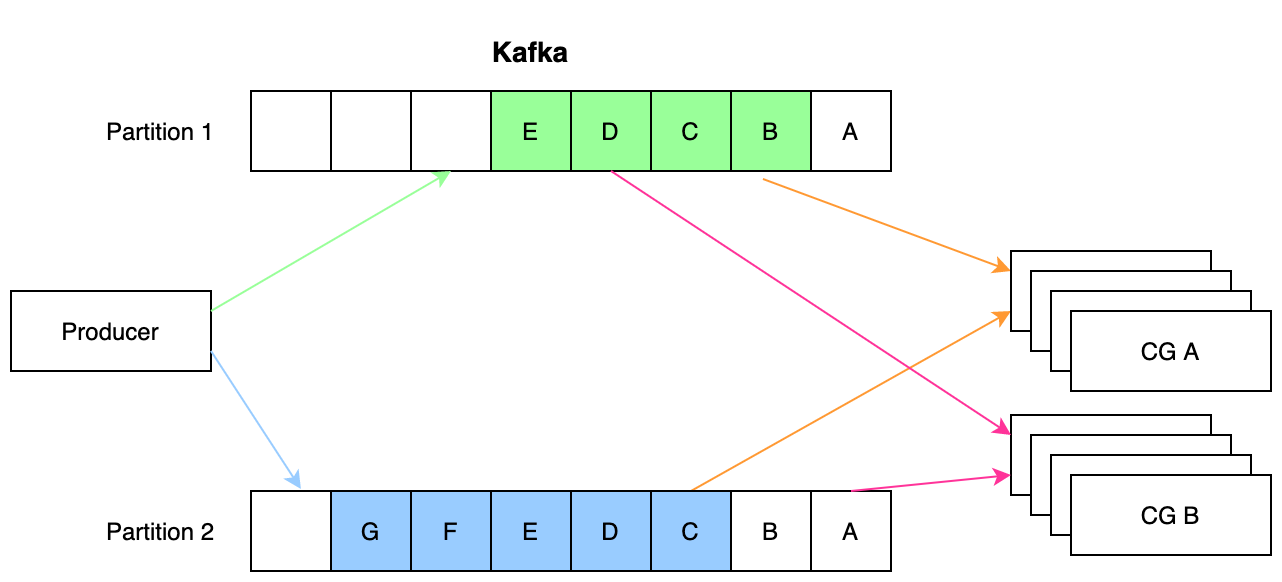
When data is written to Kafka, it’s written to a topic. A topic is made up of one or more partitions that are hosted on a broker. Generally, there are a minimum of 3 brokers in a Kafka cluster (3 is the minimum to allow a quorum election for leaders). Kafka scales by adding more brokers to a cluster with more partitions for a topic and with a replication setting for a topic. For a topic with 3 partitions and a replication factor of 2, there will be a total of 6 logical units (physically folders full of segments on disk) which could be spread over 2 to 6 brokers (Kafka won’t allow the replica of a partition to exist on the same broker as the primary partition.)
The producer service generally does a round-robin write of data to partitions but data could also be explicitly written to specific partitions based on keys. In the example image above, 12 events were written to the topic with 5 ending up on partition 1 and 7 on partition 2.
A consuming service registers with the cluster and specifies a Consumer Group (CG) name. Information about the CG is stored on the cluster in another system topic and records the offsets consumed per partition per topic. In the example image, two CGs exist; CG A has consumed up through event A on partition 1 and through event B on partition 2. CG B has consumed up through event C on partition 1 but no events yet on partition 2. The events are persisted to disk with a partition in FIFO order but not across partitions. Consumers can only have guaranteed FIFO order within a single partition (or a topic with only a single partition). If a topic only has one partition, that means there can only be a single consumer — parallel processing of FIFO data can be a real challenge. Once events have been marked as consumed, they remain on the topic until the retention setting on a topic has passed (by default 7 days).
Within a CG, there are members (generally unique containers) which are each assigned to be the owner of partitions. A partition can not be owned by more than one container at a time. This means that if we had 3 containers accessing the example topic, one would be idle and not consuming any data.
RabbitMQ Innards
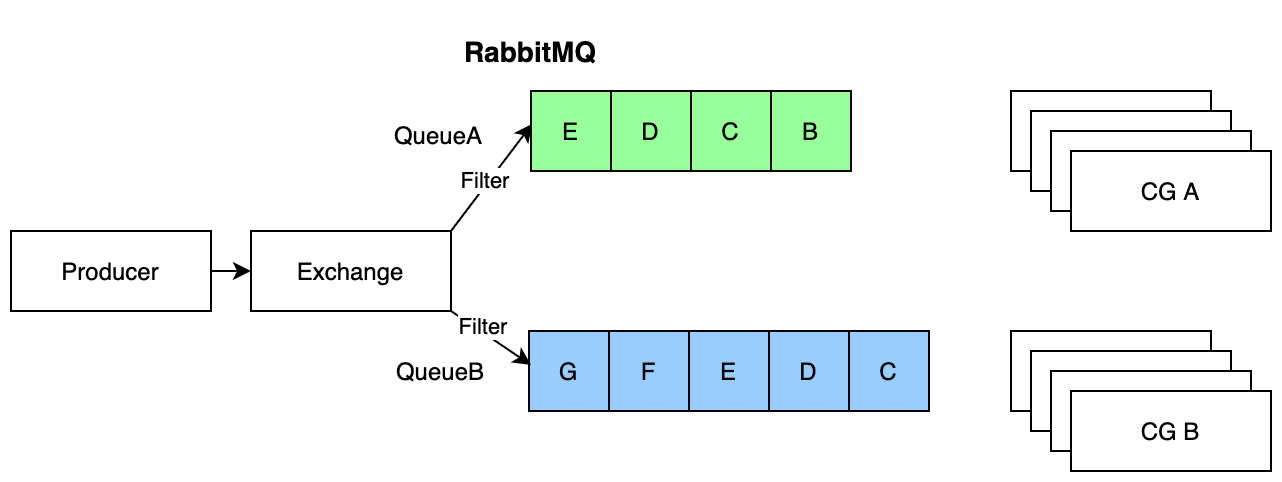
With RabbitMQ, a producer writes data to an exchange. The exchange is then responsible to filter data based on logic rules and write to queues. A set of consumer containers connect to a queue and remove events from the queues once completed. The consumers are competing consumers — whichever container completes the work first gets the next unit of work.
It’s possible to set up a consumer so it doesn’t mark work as completed. This is generally the preferred method for events when the consumer just needs to know something happened vs treating the event as a unit of work that needs to be processed at most once.
RabbitMQ traditionally stores events in memory which can be a limiting factor. There are certainly ways around this. Setting up RabbitMQ for replication and high availability is an added task.
Some high-level considerations for using Kafka vs RabbitMQ
- Replay:
- Kafka is good — Kafka is designed to persist data and we could replay the data for the whole life of the topic
- RabbitMQ is bad — Rabbit is designed to delete the data once processed.
- Routing:
- Kafka is bad — Any consumer who is permitted to receive events for a Topic receives all events which have been produced for the topic. The consumer then chooses what data it wants to consume
- RabbitMQ is good – The exchange chooses what data is written to a queue and the consumer can only receive events which have been sent to it’s specific queue
- FIFO
- Kafka is good — Kafka producers can target specific partitions within a topic and enforce FIFO ordering on write. Consumers consume in FIFO order from a partition. This does imply that there only be a single consumer per FIFO partition.
- RabbitMQ is bad — Because RabbitMQ consumers are competing consumers, event processing can be completed out of order if one event takes more time to complete than the next one.
- Priority:
- Kafka is bad — Kafka doesn’t have any concept of event prioritization.
- RabbitMQ good – With RabbitMQ, we can specify which events in a queue are higher priority and consume them with that guidance.
- Latency:
- Kafka is ok — Kafka consumers poll for new events from brokers. The polling interval can be tweaked down but that adds load.
- RabbitMQ is better – RabbitMQ pushes events to idle consumers as soon as they are received.
Possible Queue Usage Examples
There are main event types; Queue events and Pub/Sub events:
- Queue events:
- Producer has a new unit of work which must be processed (generally only once)
- Consumer processes work, tells the queueing system and it’s removed from the queue.
- Pub/Sub events:
- Publisher emits potentially interesting events
- Consumer(s) selectively listens to what it chooses as interesting
Real-Life Examples of Queue and Pub/Sub:
- Queue Events:
- Ingress Buffering: Receive an event, get it persisted as quickly as possible and send an acknowledgement back to the sender. This is great for microbursts of work. Consumers can process the events asynchronously
- Data Archival: Have a long retain time to allow new consumers to build their own view of dataset based on all those events over time.
- Event Journal: Queue up work for a while and then batch process, e.g. End of Day jobs
- Pub/Sub Events:
- State Change / Runtime Configs: Notify multiple services of feature a flag or settings changes
- Statistics: For my service, published health information and SLAs
- Local Constructed Views/ Caching: Allow other services to build more meaningful datasets based on only the information they care about
Live Use
Redox has been a heavy user of Kafka for several years now. Our primary use case is for queue events after our real-time processing has been done on patient records. We will queue the objects into one of several Kafka topics for downstream consumers for analysis and archiving needs. We run around a dozen AWS MSK clusters with many TBs worth of data being persisted every day.
Join us!
Redox is constantly hiring and we have a ton of open positions all across the company. Come check our open positions and help fix healthcare.
Stay in the know! Subscribe to our newsletter.
Related Posts

2024 HL7® FHIR® DevDays Top 5 takeaways (a newbie’s take)
Brendan from our Solutions Engineering team explores the current state of HL7® v2 and HL7® FHIR®, and how Redox can drive a FHIR-based application experience even when data exchange partners prefer to use HL7 v2.