
At Redox, we think two things are really important: our customers, and our engineers’ well-being.
Because healthcare never stops, we need our system to be healthy 24 hours a day, 7 days a week. If you’ve written and maintained complex software systems, you know that there are a multitude of things that could go wrong at any time, and thus we have to make sure that someone knows if something goes wrong at any time. To do this, we leverage PagerDuty to schedule on-call shifts for our engineers.
Having someone on call is necessary, but it’s not fun. In case something goes bump, the on-call engineer needs to be near both their phone and their laptop at all times, and they need to make sure they can get an internet connection (engineers receive Verizon MiFi devices, so a decent cell phone signal is enough). So no camping trips. No flights. My local grocery store is a Verizon dead zone, so I don’t go there without coordinating a back-up. And for engineers not well-versed in everything that could possibly go wrong, it can be anxiety inducing.
So how do we balance these two things that we care deeply about? How do we ensure that our engineers are getting the most out of their non-work lives while ensuring that our customers are receiving top-notch service?
Let’s start by talking about the before times.
The Before Times

Back in 2019, many things were a lot better than they are now. Our on-call rotation and practices were not among them.
We had week-long 24-hour-a-day shifts. This was established when we had only a few engineers, but as the engineering team grew, this meant we had a shift once every few months. Just enough time to forget everything you’d learned.
If we needed someone to cover us for any of that period, say to go to a grocery store without cell phone service, we had to figure that out for ourselves.
We got paged almost every day while on call, often for things we had little context for or control over. If you didn’t have to handle a page after hours during your shift, you felt lucky.
We had little documentation for our pages — the workflow was generally to search through Slack for the last time this happened, and hope the on-call person wrote something about it.
Not every engineer was part of the rotation, only those that were “experienced” with the product and its potential problems. This was the result of (and contributed to) tribal knowledge and lack of documentation.
We were alerted for things that weren’t actually problems, sometimes more often than for real problems. This was generally because we were alerting on causes to issues we’d seen or anticipated, rather than symptoms indicating actual problems.
When something went wrong, getting help was something you more or less had to figure out for yourself. Slack has people’s phone numbers if it’s after hours.
Don’t get me wrong, we actively tried to make being on-call less awful, we were just at a point in our growth where (a) there were higher priority things to deliver, (b) there was an overwhelming amount of on-call debt to repay, and (c) we didn’t know it could be so much better than it was.
Solving the Problem
In late 2019, one of our engineers was absolutely inundated by pages throughout their shift. This was the straw that broke the camel’s back.
In January 2020, we established the PagerDuty Task Force (PDTF) with the goal of improving the experience of being on call without sacrificing the health and stability of our product. This was accomplished by effecting change to our culture, our processes, and our systems.

Cultural Change
The PDTF came up with a set of first principles for how we approach establishing on-call best practices:
- A pageable scenario must be detected ASAP
- Pages for pageable scenarios should be sent to a human (or humans) in time to remediate, or ASAP if detection-to-impact time is as short as or shorter than manual remediation time
- Pages detract from our ability as individuals and as teams to deliver value in other ways
- Pages outside individuals’ normal working hours detract from work:life balance
- The intent of providing on-call support is to be a primary responder to pages, focusing on the triage of incoming alerts and not necessarily on fixing the root causes.
- Remediations should mature from discovery (first use), to documented (known fix), to automated (preventing the Alert from happening), where possible.
Given these principles as a baseline, we established a new cultural lens through which to observe the systems we support and processes we use to support them.
We also agreed that all application engineers should share the load of being on call in order to reduce the burden on any one of us. This had a secondary effect — having more diverse perspectives and more people to improve processes resulted in more rapid reduction of friction overall.
Process Change
Given principles (3) and (4) above, as well as feedback from our fellow on-call engineers, we reasoned that week-long shifts were not the right way to go. Therefore, we shortened shift length to 2-3 days (Monday/Tuesday, Wednesday/Thursday, and Friday/Saturday/Sunday). We also reasoned that having a designated backup to share the load would improve our work/life balance, which led us to institute a secondary schedule — everyone on call now has a designated person to go to for coverage, who is also a second line of defense in case the page cannot be acknowledged quickly enough.
Next, reasoning from principles (5) and (6), the team put together comprehensive documentation for every page in the system, and set the expectation that all engineers would own and maintain the documentation. When a new page is created, part of the definition of done is to create a documentation space for that page. When we learn new things about scenarios that cause that page, the documentation is to be updated. For teams that own those pages, the end goal should be to obviate the page.
Beyond that, we made it easy to pull others into active incidents with both PagerDuty on-call response plays and Slack workflows. Now, it only takes a few clicks to pull in members of teams with more context on problems, as well as get incident coordinators and incident communication managers involved.
Functional Change
This great blog post by Datadog gave us a better framework to think about our alerts from a technical perspective. There are two points in that article that really stuck with us:
- Alerting based on potential causes rather than symptoms of an issue is a source of burn-out
- We should assess whether an alert should be a high-priority page, a medium-priority notification, or a low-priority record
With all of these learnings, extensive documentation, and cultural change, we had new shared context that allowed us to better assess and improve our system. This empowered us to improve our system such that many pages have been completely eliminated in favor of system enhancements that remove such vulnerabilities or automatically remediate them.
Where we are now
As a reminder, our goal was to improve the experience of being on-call while making no sacrifices to the quality of our service. We took a survey of the 15 on-call engineers not on PDTF, and here were some of the results:
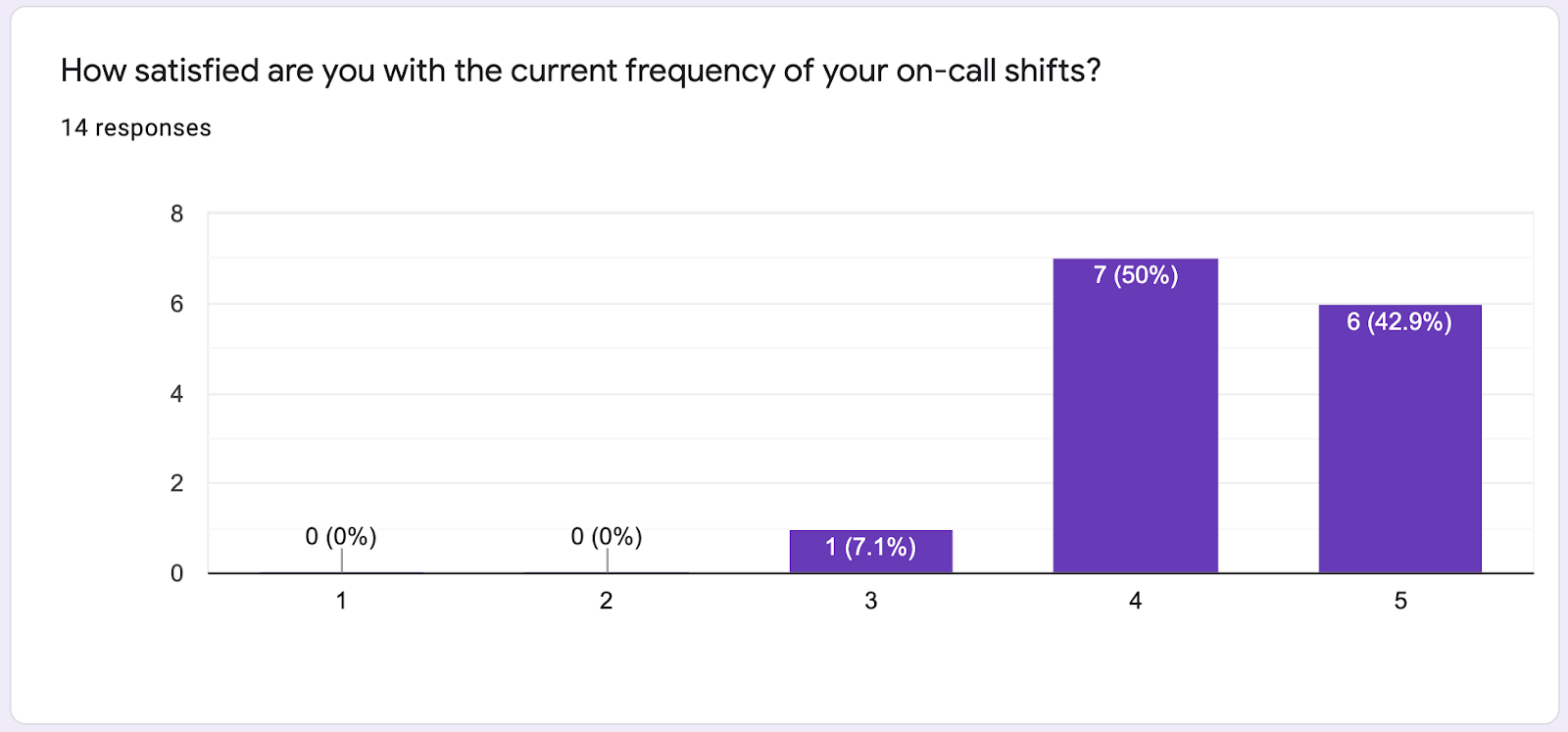
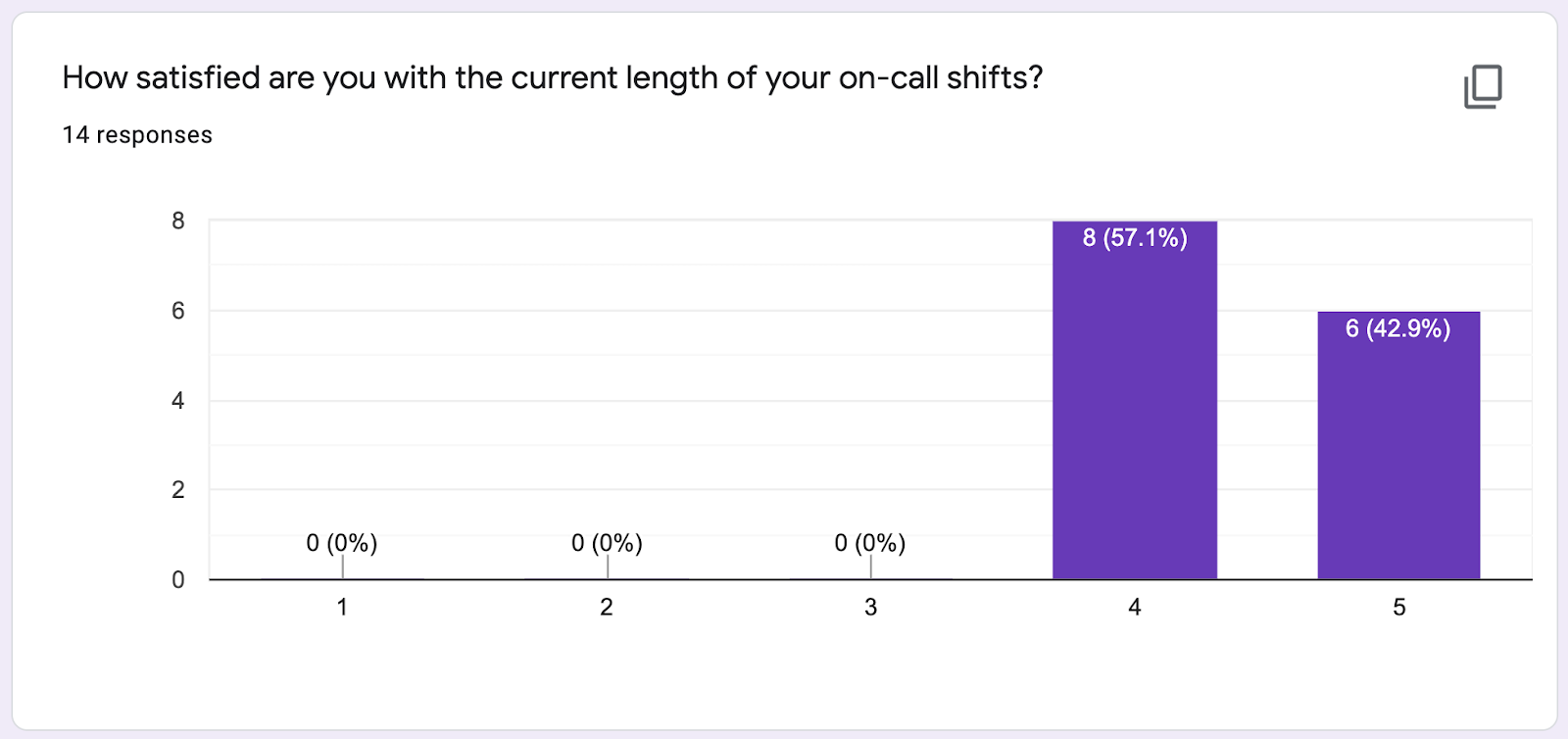
As far as frequency of pages, in October 2019, we paged our on-call developer 1174 times.

In June 2021, that number is down to 34!

From Crisis to Crickets
We have a Slack channel called #pagerduty-handoff where folks going off call communicate with those going on call. The most popular emoji/reactji there these days? Crickets 🦗🦗🦗. And we’ve seen zero cases where we’ve made a change that’s resulted in lower quality service to our customers.
We took a principles-first approach to change not just the current state, but the way we think about monitoring and supporting our product. We changed the culture, processes, and product to better strike the balance between supporting our product and supporting our people. We didn’t just whittle down the mountain of sadness — we’ve prevented the mountain from building in the future.
Stay in the know! Subscribe to our newsletter.
Related Posts
Redox FHIR API search update
We’re excited to announce an update to the Redox FHIR API that enhances data query capabilities by no longer filtering unrecognized search parameters. This change gives you greater control over your data interactions and improves integrations with downstream systems.
