

Hey there! Brandon Palmer here.
Some FIFO (First In, First Out) event streams are idempotent such that order doesn’t matter and can be sorted by date; web logs are one example. There are other situations where the order of the events must be processed in exact FIFO order and any violation would make the data logically incorrect. One such example would be healthcare data, where a patient must be admitted before they can be discharged since admission data may also be included in the discharge event. While maintaining this perfect order, we also need to make sure we sustain a reasonable latency through the system regardless of the event velocity we are receiving. This blog will describe one solution to that need.
The manifestation of our challenge
For most systems, we care about latency for an event to be processed — the amount of time between receipt and completion of processing. When those events must be processed in FIFO order, the longer it takes to process each event, the higher our latency will become.
When a system receives an event, it will take a finite amount of time to process that event and then pass it on to the next phase. If the time to process the event is higher than the number of events we receive per time interval, the upstream system will begin to queue up events waiting to be sent:
- It takes 200ms for us to process an event and pass it to the next phase.
- If we receive more than 5 events per second, we will be unable to keep up with the data flow and the upstream system will need to wait.
We could add a queue on the front side to quickly receive the events for asynchronous processing which would hide the problems from the upstream. We now buffer the flow to hide the issue from the upstream system but we’ve only deferred solving the problem.
Improving the processing time is beneficial but the inflow velocity could still overwhelm us at a high enough velocity.
This problem becomes even more complex when there are possibly thousands of independent FIFO streams at different speeds; we need to have a finite number of containers which would process events from any queue. Depending on how the consumers are designed, a noisy-neighbor queue (high volume) could easily cause significant latency for lower volume queues.
The ideal architecture would be having multiple containers which could process events in parallel in the FIFO streams while still maintaining the order as they are completed. That is the problem we solve with the FIFO Parallel Processing model. This process has been patented by Tanner Engbretson, Brandon Palmer and Blake Rego but has also had continual development by numerous highly skilled engineers at Redox.
How we have solved this problem
To solve this problem, we’ve taken the processing of a single event and broken it down into two phases; the first being the more time intensive portion of concurrent processing and the second being the low time intensity portion of sequential processing. In our implementation, every event is a row in a Postgres database with the payload stored along with the event metadata.
Concurrent Processing
We have a pool of concurrent processing containers, scaled to service our event volume. While targeting a single queue at a time, each one of these containers chooses a random event within a configurable window from the head of the queue and marks the event as in-process (locked-concurrent, orange). There are back-off timers when there aren’t any events in the queue to be processed.

Shown here, we will presume there are 4 containers and events a,b,d and e have been chosen and locked. A timer is set on each event when the lock is taken and any other container can choose a locked event if the timer has passed a certain timeout setting (this allows the event to be reprocessed when a container crashes or exits). The concurrent processing work is done on the event (taking anywhere from 5ms to 60,000ms depending on the needed computational work), the computed payload is saved to the queue and then the event is marked as processed-concurrently.
Sequential Processing
We have another set of sequential processing containers, scaled to service the number of active queues with events (that will be explained further in the multi-queue section). A sequential container looks at a windowed head of the queue and pops processed-concurrent (blue, a and b in this case) events off the queue and sends the events on to the next phase (this presumes very low latency to send to the next phase; we generally see < 5ms per event).

Once the sequential processor reaches an event which isn’t in a processed-concurrent state, it will move on to the next queue. There are built-in back-down timers when there is no work to be done.
One important component of the patent is how the sequential container efficiently finds the candidate head events to pop. Within the window, it first sequentially numbers all events, then sequentially numbers the processed-concurrent events and lastly compares the two sets. Any events which have a difference of zero are ready to be popped.
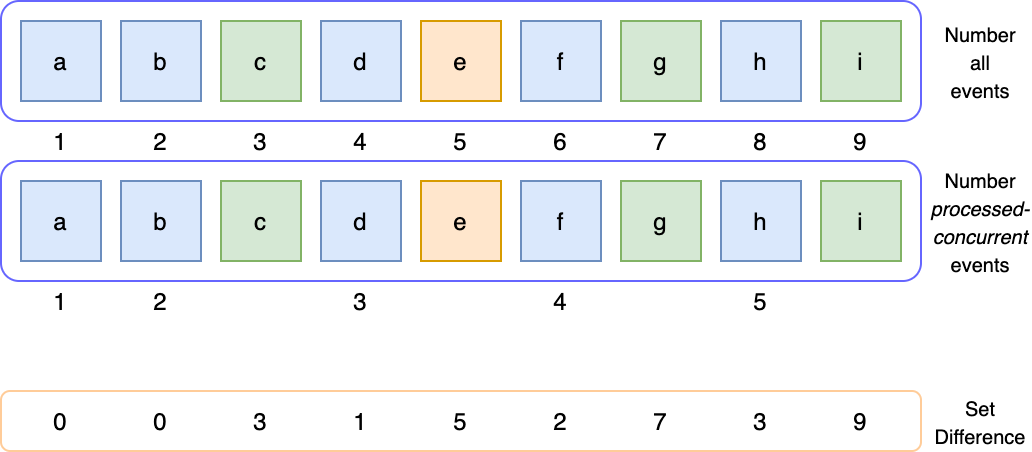
With these two combined sets of containers, we can process the long-running work in parallel but then send FIFO events as soon as they are completed. The theoretical processing limit per queue is gated by the sequential execution latency.
How does this work with large numbers of queues?
We work with tens of thousands to hundreds of thousands of queues, all at varying event throughput. We need to ensure that queues with low event volume aren’t neglected in favor of queues with high event volume (queue starvation). This helps to ensure all queues have reasonable latency regardless of noisy-neighbor volumes. It’s not scalable to dedicate concurrent or sequential containers to specific queues so we need to make sure a single type of container could process any queue.
Concurrent Processing
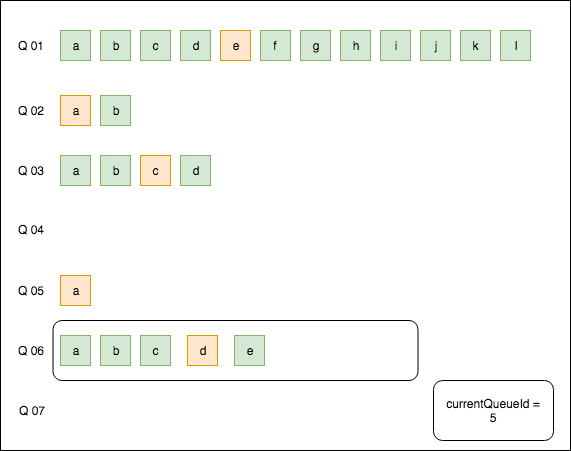
Our queues are numbered in the database and concurrent consumers will loop through all queues, one at a time, and process events as they go. Once there are no queues left (we’ve reached the highest queue number), the CurrentQueueID counter will be reset to zero and we will begin the loop again. As shown in the below image, the container has processed Q01 event e, Q02 event a, Q03 event c, Q05 event a and is currently selecting event e from Q06. Once complete, there will be no queues left with events and the counter will be reset back to zero to begin the looping process again. We track a bunch of timing metrics (loop time, number of queues with work, stolen events from TTL expiration, etc) to perform fine tuning of windows, sleep timers and work TTL. There are backoff timers if we complete a loop without finding queues to work on.
Sequential Processing
The sequential processing containers will behave in a very similar manner; looping over all queues which have processed-concurrent events and finding head events which need to be popped. A sequential processing container is limited to the events in one queue at a time to preserve FIFO for that queue. Due to the latency sensitivity of this step, the queue head bite sizes need to be much more carefully adjusted. From the below image, a full loop would pop events a,b,c,d from Q01 (e is still concurrent-locked so not ready to go), event a from Q02, nothing from Q03, a from Q05 and a,b,c,d,e from Q06

This is an oversimplification of real-world operation
Redox has been using an expanded and optimized version of this technology (internally known as FQS for FatQSlim) for several years and a great deal of detail has been skipped for this blog post; the details are specific to RedoxEngine’s data profile and volume demands. Once this technique is deployed into production, there are added operational needs for queue pausing / unpausing, swim-lanes, queue prioritization and SQL tuning. The size of each event (some are upward of 100Mb) and the volume of database row changes have driven the need for considerable query and database optimization to keep the queries performant.
Redox is currently running over 500 concurrent + sequential containers spread over 5 Postgresql RDS shards (for failure isolation) to process over a billion medical events per month in perfect FIFO order.
This post, in its original form, can be read on my personal blog. Cheers!
This is part one of a series. Check out part two and part three to learn more.